本センターでは
• HITACHI SR11000/J2
• HA8000クラスタシステム(T2Kオープンスーパーコンピュータ)
の2式のスーパーコンピュータシステムをサービスしています。この利用の手引は「HA8000クラスタシステム」について解説します。
HA8000クラスタシステムは「T2Kオープンスーパーコンピュータ」として筑波大学、京都大学と共同で仕様を策定したスーパーコンピュータです。仕様を共同で策定したため3大学の計算センターに構成の似たスーパーコンピュータが導入されていますが、本センターでは特に東京大学情報基盤センターに導入されたT2Kオープンスーパーコンピュータを意味する名称として「HA8000クラスタシステム」を用います。この名称は本センターのT2Kオープンスーパーコンピュータの各ノードである計算機の製品名である「HITACHI HA8000-tc/RS425」の名前に由来します。
従来のスーパーコンピュータは「ベクトル化」に代表される特殊な最適化が必要でプログラムの汎用性が低くなる傾向がありましたが、HA8000クラスタシステムは多くの人に手軽に使っていただける環境を提供するため特殊な技術を使わない設計となっています。具体的には特徴は次の3点です。
• パーソナルコンピュータやクラスタシステムなどで広く使われている x86 系プロセッサを搭載しているため、特殊なソフトウェアや最適化が不要
• Linux オペレーティングシステムを採用しているため、一般的なPCクラスタとほぼ同じ操作で使用可能
• 多数のプロセッサと高性能ノード間接続による高性能計算が可能
つまり、オープンスーパーコンピュータは、PCクラスタの利点を備えつつプロセッサ数と通信性能を強化した並列計算機ということになります。
本章ではHA8000クラスタシステムのハードウェア構成を紹介します。
1.3.1 全体構成
HA8000クラスタシステムは16個のプロセッサを持つ計算機952台を高速ネットワークで接続したクラスタ型並列計算機です。全体構成は下の表のようになっています。
表1 HA8000クラスタシステム全体性能
|
項目 |
仕様 |
|
|
全体性能 |
理論演算性能 |
140.1344TFLOPS |
|
主記憶容量 |
31.25TB |
|
|
ノード数 |
952(512+128+256+56) |
|
|
ノード間ネットワーク性能 |
5 GB/s×双方向(計算ノード群A) 2.5 GB/s×双方向(計算ノード群B) |
|
|
ストレージ容量 |
1PB (RAID6: 実効容量) |
運用上、一個のアプリケーションが952台全体を使用することはないので、図1のように952台は512台、128台、256台、56台に分割されて接続されています。また、512台のクラスタと128台のクラスタはノード間が5GB/sで接続されており、256台のクラスタと56台のクラスタはノード間が2.5GB/sで接続されています。5GB/s接続のクラスタをタイプA、2.5GB/sのクラスタをタイプBと呼びます。
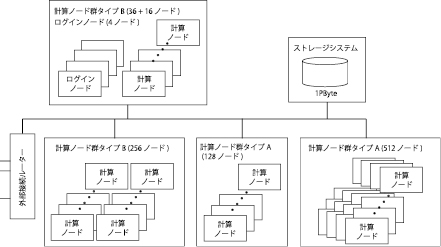
図1 HA8000クラスタシステム全体構成
このようにHA8000クラスタシステムは4組のクラスタとストレージシステム、外部接続ルーターがネットワークで接続された構成になっています。クラスタ間およびクラスタとストレージシステムの間は1.25GB/sから7.5GB/sのネットワークで接続されています。
1.3.2 クラスタ内の構成
それぞれのクラスタはAMD Quad Core Opteron プロセッサを4個(合計16コア)搭載したノードをMyrinet-10Gインターコネクトで接続したものとなっています。Myrinet-10Gは1リンク1方向あたり1.25GB/s のバンド幅を持ち、双方向同時通信が可能です。タイプAのクラスタは1ノードあたり4本のMyrinet-10Gを搭載しているので5GB/s、タイプBは2本なので2.5GB/sとなります。各クラスタ内ではMyrinet-10Gは「フルバイセクションバンド幅」が確保される方法で接続されています。フルバイセクションバンド幅の構成とはクラスタ内の任意の半数のノードが同時に残り半分のノードにデータを送信してもネットワーク内での競合が発生しないネットワーク構成を意味します。図 2に16ポートのスイッチを24個使用して128ノードのフルバイセクションネットワークを構成する例を挙げます。実際のHA8000クラスタシステムでは32ポートのチップを多数搭載した512ポートスイッチを使用しているため、図2は実際の配線を示しているわけではありませんが、方式としては実際のシステムと同じです。多くの接続でバンド幅が確保されていることがおわかりいただけるかと思います。
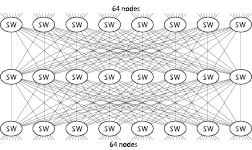
図2 ネットワーク構成
1.3.3 ノードの構成
HA8000クラスタシステムの各ノードはクアッドコアプロセッサ4個、つまり16コアのCPUを搭載しています。表2にノードの主な仕様を示します。AMD Quad Core Opteron 8356プロセッサは1クロックに4回の浮動小数点演算ができるので、2.3GHzの場合、1コアあたりの演算性能は 2.3 x 4 = 9.2GFlops です。各ノードは16個のプロセッサコアを搭載しているため、演算性能は 9.2 x 16 = 147.2GFlopsとなります。
表2 HA8000ノードの諸元
|
ノード |
理論演算性能 |
147.2GFLOPS |
|
プロセッサ数(コア数) |
4 (16) |
|
|
主記憶容量 |
32GB (936 ノード) 128GB (16ノード) |
|
|
ローカルディスク容量 |
250GB (RAID1 OS領域含む) |
|
|
プロセッサ |
プロセッサ(周波数) |
AMD Quad Core Opteron 8356 (2.3GHz) |
|
キャッシュメモリ |
L2: 512KB/コア L3: 2MB/プロセッサ |
|
|
理論演算性能 |
9.2GFLOPS |
各ノードは図3のように構成されています。32GB(一部128GB)のメモリは4つに分割されて各プロセッサに接続されていますが、すべてのプロセッサからすべてのメモリにアクセスができます。ただし近くのメモリにアクセスする場合と遠くのメモリにアクセスする場合で性能が異なるので、アプリケーションの最適化の際には注意が必要です。
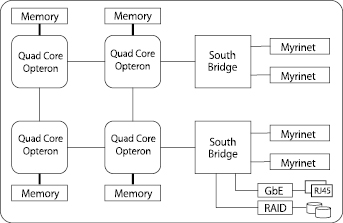
図3 ノード構成
HA8000クラスタシステムにインストールされている主なソフトウェアは表3のとおりです。
表3 ソフトウェア一覧
|
項目 |
ソフトウェア名 |
|
OS |
RedHat Enterprise Linux 5.1 |
|
シェル |
bash/sh tcsh/csh zsh |
|
バッチシステム |
日立製NQS |
|
コンパイラ |
日立製作所製 最適化Fortran 77/90/95 日立製作所製 最適化 C 最適化標準C++ Intel Compiler C/C++/Fortran Version 11 PGI Conpiler 7.1 (アカデミックユーザーのみ) |
|
並列計算通信ライブラリ |
MPICH-MX (MPI 1.2) |
|
数値計算ライブラリ |
MSL2、MATRIX/MPP、MATRIX/MPP/SSS BLAS、LAPACK、ScaLAPACK Intel Math Kernel Library、ACML GotoBLAS |
|
分子計算アプリケーション |
Gaussian03 |
これらのソフトウェアはログインノードまたは計算ノードで使用できます。ログインノードではSSHによるログインおよびコマンドの対話的実行が可能です。主にプログラムの作成・編集,コンパイル,バッチジョブの投入に使用します。ログインノードの資源は多くのユーザーで共有しますので重い処理は行わないようにしてください。計算ノードはバッチジョブシステム(NQS)を通じて使用します。ジョブを投入してから実行されるまでに待ち時間がありますが、自分の順番が回ってきた際には計算ノードの資源を専有できます。通常、すべてのユーザープログラムはバッチジョブとして計算ノードで実行します。
本システムは広く使われている x86 系プロセッサと Linux の組み合わせで構成されているので、多数のフリーソフトウェアや市販のソフトウェアが動くことが期待できます。本センターがサービスとしてインストールしていないソフトウェアは、ユーザー個人のホームディレクトリにインストールしていただくことで利用可能です(ただし、管理者権限が必要なソフトウェアは使用できません)。
HA8000クラスタシステムでは研究者が個人単位で利用するための「パーソナルコース」、研究グループ単位でまとまった資源を確保するための「専用キューコース」、スーパーコンピュータの一部を専有利用できる「ノード固定コース」を準備しています。それぞれのコースのサービス内容は次の通りです。
1.5.1 パーソナルコース
パーソナルコースは希望される資源量に応じて下のようなコースがあります。
表4 パーソナルコースの種類
|
コース名 |
使用可能 |
使用可能 |
資源割り当て方式 |
|
パーソナル1 |
4 |
100GB |
パーソナルコースの他の利用者と共有し、Fair Share 方式によって実行順序を決定 |
|
パーソナル2 |
8 |
100GB |
|
|
パーソナル3 |
16 |
100GB |
|
|
パーソナル4 |
32 |
100GB |
|
|
パーソナル5 |
64 |
100GB |
上位コースは下位コースを含みますので、例えばパーソナルコース5の利用者が16ノードのジョブを実行することは可能です。また、デバッグのための4ノード5分のキューやパラメーターチューニングなどのために4,8,16ノードについては実行可能時間が短い代わりに待ち時間も短い short キューが準備されています。
さらに、利用者のプログラムの大規模化を支援するため、申し込みコースの上限より大きなジョブを月に一回だけ実行できます(大規模ジョブ実行サービス)。このジョブは申込コースより1レベル高いコースの上限ノード数(パーソナル1の方は8ノード、など)を利用できます。パーソナル5の方は256ノードジョブが実行できます。
1.5.2 専用キューコース
専用キューコースは研究グループなどで利用されるためのコースです。8ノード単位でご希望のノード数が申込みいただけます(利用者数によってはご希望に添えない場合があります)。標準ディスク容量は8ノードあたり4TBです。また、64ノード以上をお申し込みのグループは月に一回の256ノードジョブが実行可能です。
このコースではバッチジョブキューがご希望のポリシーで作成できます。例えば、16ノードを申し込みの上で8ノードジョブが同時に2本流れるようなキューと16ノードジョブ用のキューを作成するなどの設定が可能です。次に紹介するノード専有との違いは、物理ノードを他の専用キューコースの方と共有することです。例えば16ノードを申し込むグループが20グループあっても、320ノードでなく240ノード程度しか割り当てを行いませんので、自グループのジョブが一個も実行されない時間帯が存在します。公平な資源分配のため、ジョブの実行時間は原則48時間以内とさせていただきますが、特別な理由がある場合は「制限時間延長申込書」をご提出下さい。センターで延長の可否を決定させていただきます。
1.5.3 ノード固定コース
ノード固定コースは、ノード数を確定する必要のある商用ライブラリの利用や、利用環境をカスタマイズする必要があるユーザー向けのコースです。例えば利用ノードが一定しない専用キューコースではライセンス代が非常に高価になるソフトウェアをご利用の場合、あるいはローカルディスクの使用ポリシーをカスタマイズするなどの必要がある場合にお申し込みいただけます。8ノード単位での申し込みができます。標準ディスク容量は8ノードあたり4TBです。64ノード以上ご利用のグループは月に一回256ノードジョブが実行できます(専有利用しているノードとは別のノードを使用します)。
なお、ノード固定コースにお申込の場合は、「ノード固定コース 申込時添付書類」のご提出をお願いします。センターでご使用の可否を決定させていただきます。