HA8000クラスタシステムではすべてのプログラムがバッチジョブシステム(NQS)を通じて実行されます。HA8000クラスタシステムでは 日立製作所製のNQSが導入されており、本センターの他のスーパーコンピュータと同じジョブスクリプトが使用できます。
ジョブを実行するにはまず実行するプログラムとは別に「ジョブスクリプト」と呼ばれるファイルを作成します。ジョブスクリプトには希望する実行時間に見合ったキューの名前、使用CPU数などを記述した上で、実際にプログラムを実行するためのコマンドを書きます。このファイルが完成したら qsub コマンドでこのジョブをNQSに登録し実行を待ちます。ジョブに資源が割り当てられると、ジョブスクリプトに記述したコマンドが自動的に実行されます。実行結果はファイルに残りますのでジョブ投入後はログインしている必要はありません。ジョブの状態は qstat コマンドで確認できるほか、開始と終了はログインノードにメールで通知されます。3章で説明した転送設定を行うかジョブスクリプトに送信先を設定することで、普段使用しているメールアドレスにジョブ完了通知を送信することもできます。
バッチジョブシステムの待ち行列には「バッチキュー」と呼ばれるジョブの待ち行列と「パイプキュー」と呼ばれる他のキューにジョブを転送するためのキューがあります。バッチキューは要求されたプロセッサや計算時間別に準備されており、実行待ちのジョブはバッチキューに入ります。一方パイプキューはジョブの振り分けを行うキューであり、パイプキューに投入されたジョブは必要としている資源量に応じて適切なバッチキューに自動的に転送されます。
HA8000クラスタシステムでは図13のようにパイプキューとバッチキューが準備されています(実際に利用できるキューは申込コースによって異なります)。点線で囲まれたバッチキューは必ずパイプキュー経由で使用する必要があり、直接キューを指定してジョブを投入することはできません。debug キューや専用キューコースのキューは直接バッチキュー名を指定してジョブを投入します。
※ 利用できるコースの詳細はセンターホームページの「ジョブクラス制限値」をご覧ください
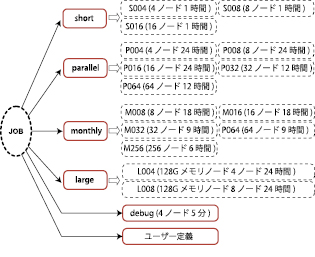
図13 HA8000クラスタシステムのキュー
ジョブスクリプトは次のような構成のテキストファイルです。
#!/bin/bash
#@$-q parallel
#@$-N 4 #@$- から始まる行でバッチジョブの属性を設定する
#@$-J T4
#@$-lT 8:00:00
cd program
mpirun ./a.out 実行するシェルスクリプトを記述する
date
このようにジョブスクリプトには #@$- から始まるバッチジョブのオプション指定部分とその下のシェルスクリプト部分があります。バッチジョブシステムはオプション部分を使用して投入するバッチキューを決定し、順番が回ってきた際にはスクリプト下部のシェルスクリプトを実行します。9章でも具体的なジョブスクリプトの例を紹介します。ジョブスクリプトは、大文字、小文字が区別されるのでご注意ください。
7.3.1 主要オプション
次に挙げる2項目はすべてのジョブスクリプトに必要です。
|
オプション |
内 容 |
指 定 例 |
|
#@$-q |
パイプキューの名前 |
#@$-q parallel |
|
#@$-N |
ノード数 |
#@$-N 4 |
q および N オプションの値を用いてバッチジョブキューが決定されます。Nの値はバッチキューのノード数に一致している必要はありません。例えば10ノードを指定した場合は16ノード用のバッチキューに挿入されます。
次の2項目は必須ではありませんが、指定することをお勧めします。
|
オプション |
内 容 |
指 定 例 |
|
#@$-J |
ノードあたりのプロセス数 |
#@$-J T4 |
|
#@$-lT |
予想実行時間 |
#@$-lT 8:00:00 |
Jオプションには T に続けてノードあたりのプロセス数を書きます。省略時は1となります。Tが必要なのはSR11000以前のシステムとの互換性のためです。SR11000で使用している S および SS の指定も可能ですが、新たに作成するスクリプトでは使用しないことをお勧めします。lT(小文字エル、大文字ティー)オプションはジョブ実行の最大時間であり、この時間を超えるとジョブは強制終了となります。lTオプションを省略すると各パイプキューの最大時間とみなされますが、効率的な資源利用のために指定をお願いします。
7.3.2 その他のオプション
必須オプションの他に以下のオプションが使用できます。
|
オプション |
内 容 |
指 定 例 |
|
#@$-lM |
ノードあたりのメモリーサイズ |
#@$-lM 4GB |
|
#@$-e |
標準エラー出力ファイル名 |
#@$-e file.e |
|
#@$-o |
標準出力ファイル名 |
#@$-o file.o |
|
#@$-eo |
標準エラー出力の内容を標準出力ファイルに出力 |
#@$-eo |
|
#@$-mu |
メールの送信先 |
#@$-mu xxx@xxx.jp |
|
#@$-lc |
コアファイルサイズ |
#@$-lc 0MB |
|
#@$-ld |
プロセス毎のデーターサイズ |
#@$-ld 2GB |
|
#@$-ls |
プロセス毎のスタックサイズ |
#@$-ls 192MB |
|
#@$-lm |
プロセス毎のメモリーサイズ |
#@$-lm 2GB |
|
#@$-lt |
プロセス毎のCPU時間制限 |
#@$-lt 30:00 |
7.3.3 シェルスクリプト部分
シェルスクリプト部分には先頭行で指定したシェルが解釈できるシェルスクリプトを記述します。シェルスクリプトは常にホームディレクトリをカレントディレクトリとして開始します(ジョブスクリプトのあるディレクトリではありません)。したがって通常はプログラムが存在するディレクトリへの移動が必要です。また、このスクリプトは端末から切り離された状態で実行されるのでエディタなどの対話的なプログラムの起動を含めることはできません。
7.4.1 ジョブの投入
ジョブの実行のためにはスクリプトファイルをバッチシステムに投入(サブミット)します。コマンドは qsub を使用します。以下の例でjob.sh は既存のスクリプトファイル名とします。
$ qsub job.sh
Request “Request ID” submitted to queue: P004.
NQSはジョブを識別するリクエストID(リクエスト番号+ジョブ投入ホスト名)付加し、バッチシステムにジョブを送り込みます。利用者一人が複数のジョブを投入することもできますが数に制限があります。
7.4.2 ジョブの確認
ジョブの状態(待機中や実行中)はqstatコマンドで知ることができます。
$ qstat
2008/06/01 (Sun) 13:47:21: BATCH QUEUES on HA8000
NQS schedule stop time : 2008/06/27 (Fri) 9:00:00 (Remain: 474h 42m 39s)
REQUEST NAME OWNER QUEUE PRI NICE CPU MEM STATE
1425.batch1 job.sh p08000 P004 63 0 unlimit 28GB QUEUED
リクエストID、スクリプト名、ログイン名が表示されている行が先程投入したジョブの状況です。ジョブはバッチキューP004で待機(QUEUED)していることがわかります。出力の2行目には次の計画停止までの時間も表示されています。ジョブの予想実行時間が計画停止までの時間より長い場合は、計画停止からの復旧後までスケジューリングされません。ジョブが実行を開始するとqstatの結果は実行中(RUNNING)になります。待機中,または実行中のジョブがないときは No requests. となります。
7.4.3 キューの状態確認
キューごとの実行ジョブ,待ちジョブ数は以下のように qstat -b で確認できます。
$ qstat -b
2008/06/01 (Sun) 13:47:21: BATCH QUEUES on HA8000
NQS schedule stop time : 2008/06/27 (Fri) 9:00:00 (Remain: 474h 42m 39s)
QUEUE NAME STATUS TOTAL RUNNING RUNLIMIT QUEUED HELD IN-TRANSIT
S004 AVAILBL 1 1 6 0 0 0
S008 AVAILBL 7 3 3 4 0 0
RUNNINGが実行中のジョブの数、RUNLIMITが同時に実行できるジョブの数、QUEUEDが順番待ちのジョブの数です。
7.4.4 ジョブのキャンセルまたは強制終了
投入したジョブをキャンセルしたいとき、または実行中のジョブを強制終了したいときは qdel コマンドを使用します。
$ qdel 1425.batch1
7.4.5 ジョブの終了通知と結果確認
ジョブが終了するとジョブスクリプトの-mu オプションで指定したメールアドレス(省略時はHA8000クラスタシステムのアカウント)にメールが届きます。ジョブの出力は次のファイルに保存されています。
標準出力: スクリプトファイル名.oN (Nはジョブ番号)
標準エラー出力: スクリプトファイル名.eN (Nはジョブ番号)
7.4.6 システム障害時の動作
システム障害でジョブが途中で終了してしまったときは異常終了したジョブの名前とジョブ番号を個別にご連絡します。お手数ですが再度実行をお願いいたします。ファイル状態などが再実行が可能な状態かどうかセンターでは判断できませんので、自動的に再実行を行うことは致しません。
実行待ちのジョブは「フェアシェアスケジューリング」と呼ばれる方式で実行順序が決まります。この方式では過去に使った計算資源が少ない利用者が優先されます。ジョブの投入順序と実行順は基本的には一致しません。専用キューコースまたはノード固定コースでは投入順に実行される「FIFOスケジューリング」のキューを作成することもできます。
7.5.1 フェアシェアスケジューリングの詳細
フェアシェアスケジューリングシステムは、4月から現在までに実行済みのバッチジョブにて使用したCPUの使用量(以下,CPU使用量とする)と投入したジョブに設定した実行予定時間より算出されるCPUの予定使用量(以下CPU予定使用量とする)から各ジョブの実行優先度を決定しています。具体的なスケジューリングルールは次のようになっています。
• 各キュー毎に実行待ちのジョブにそれぞれ優先順位(63が最優先で0まで)を付け、順位の高いジョブから順に実行します。
• 順位付けの要素は,4月から現在までに実行したバッチジョブのCPU使用量を利用者毎に積算した値と、投入したバッチジョブで要求しているCPU予定使用量を合計したものであり、その値が少ないジョブから順位付けを行います。CPU使用量とは「ジョブの実行時間×使用したコア数」です。
• いずれかのジョブが終了する毎に当該利用者のCPU使用量を積算し、順位の付け替えを行います。大規模計算を行う利用者が不利とならないよう一定時間毎にCPU使用量に一定の逓減率を掛け逓減する仕組みとしています。
• キューに並んでいる際の待ち時間は順位付けの要素に含みません。
• ジョブの実行は2つまで同時に可能です。ただし同一のキューでは1つとなります。
• ジョブの優先順位はqstatコマンドの "PRI" の値で確認が可能です。