本章ではHA8000クラスタシステムを使用例として、一般的な次の2パターンについて、プログラムのコンパイルと実行方法を紹介します。
• ピュアMPIで32ノード512プロセスのプログラムを実行する場合
• ノード内はOpenMP 4スレッド×4プロセスで、32ノード128プロセス、512スレッドで実行する場合
本節ではピュアMPIプログラムのコンパイルおよび実行例を紹介します。
9.2.1 プログラムのコンパイル
ソースプログラムは program.f と仮定します。コンパイルは次のように行います。
$ mpif90 –Oss –noparallel –o program program.f
各プロセスは単一スレッドで動作するので -Ossに含まれる自動並列化オプションを無効にするよう
–noparallel をつけることが重要です。
9.2.2 ジョブスクリプトの作成
ジョブスクリプトは次のようになります。
#!/bin/bash
#@$-q parallel
#@$-N 32
#@$-J T16
#@$-lT 8:00:00
cd program/
mpirun ./program
パイプキューの名前は適宜変更が必要です。上の例では32ノード実行で各ノードに16プロセスを生成する設定が書かれています。シェルスクリプト部分では実行可能ファイルが存在するディレクトリに移動し、mpirun コマンドによってMPIプログラムを起動しています。
9.2.3 プログラムの実行
前のステップで作成したジョブスクリプトprogram.job を引数にして qsub コマンドを実行します。
$ qsub program.job
9.2.4 結果の確認
実行が終了するとカレントディレクトリに program.oXXXXX と program.eXXXXX というファイルができます。XXXXXはジョブ番号です。これらがそれぞれ標準出力と標準エラー出力の内容です。
本節ではOpenMPとMPIのハイブリッドで並列化して実行する例を紹介します。
9.3.1 プログラムのコンパイル
ソースプログラムは program_mp.f と仮定し、OpenMPディレクティブが書かれていることを仮定します。このプログラムを次のようにコンパイルします。
$ mpif90 –omp –Oss –o program_mp program_mp.f
9.3.2 ジョブスクリプトの作成
プログラムを1ノードあたり4プロセス、1プロセスあたり4スレッドとし、32ノードで実行するためのジョブスクリプトの例を示します。JオプションにはノードあたりのMPIプロセス数を設定するのでこの場合は4となります。また、各プロセスはOpenMPのスレッド4本で並列化するので OMP_NUM_THREADS 環境変数を4に設定します。
#!/bin/bash
#@$-q parallel
#@$-N 32
#@$-J T4
#@$-lT 8:00:00
export OMP_NUM_THREADS=4
cd program/
mpirun ./program_mp
9.3.3 プログラムの実行と結果の確認
プログラムの実行方法と結果の確認方法は前節の例と同じです。
最後の例としてHA8000クラスタシステムでなるべく高いアプリケーション性能を得るために少し工夫をした実行方法を紹介します。HA8000クラスタシステムの各ノードは図14のように各プロセッサにメモリが直結されています。計算中のCPUがメモリアクセスを行う際、自身に直結されているメモリにアクセスするのは高速ですが、他のCPUに接続されているメモリにアクセスする場合は時間がかかります。このように共有メモリ計算機でありながら、アクセスするメモリの場所によって性能が異なる計算機アーキテクチャを「NUMA(Non-Uniform Memory Access)アーキテクチャ」と言います。本節ではNUMAアーキテクチャ計算機でのアプリケーション実行を高速化するために、プロセスが使用するCPUとメモリの配置を固定し、なるべく高速なメモリを使用して並列ジョブを実行する方法を紹介します。
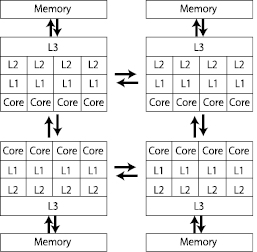
図14 NUMA構成
9.4.1 プログラムのコンパイル
プログラムのコンパイル時にNUMA最適化を行う必要はありません。前に挙げた例と同じようにコンパイルできます。利用者自身で日立製でないコンパイラや独自のライブラリをインストールした場合は、それらのコンパイラやライブラリがNUMA最適化を行わないことを確認してください。異なる二通りの最適化を行うとそれらが衝突してうまく動かない場合があります。
9.4.2 NUMA最適化スクリプトの準備
次のシェルスクリプトを準備してください。ここでは ~/numarun という名前にします。実行権限を付けておいてください。ここでは前節のOpenMPとMPIのハイブリッド実行をNUMA最適化します。このスクリプトは環境変数からMPIのランク番号を調べ、それを4で割った余りで使用するCPUを決定します(--cpunodebindオプション)。各MPIプロセスに属す全スレッドがこのCPUに固定されるため、スレッドは同じCPUの別のコアに割り当てられることになります。また、使用するメモリの位置も固定し(--membindオプション)CPUに直結されたメモリを優先的に使用します。
#!/bin/bash
MYRANK=$MXMPI_ID
NODE=$(expr $MYRANK % 4)
/usr/bin/numactl --membind=$NODE --cpunodebind=$NODE $@
このスクリプトは本システムのMPIであるMPICH-MXに強く依存しています。使用するMPIによってランク番号が格納される環境変数が異なるので、お手元のクラスタなどに応用する場合は注意が必要です。
9.4.3 ジョブ投入
ジョブスクリプトは次のように書きます。前節の OpenMP 4スレッド + MPI のハイブリッド実行の例を NUMA 最適化します。
#!/bin/bash
#@$-q parallel
#@$-N 32
#@$-J T4
#@$-lT 8:00:00
export OMP_NUM_THREADS=4
cd program/
mpirun ~/numarun ./program_mp
ジョブスクリプトも通常の実行とほとんど差がありません。mpirun で実行するプログラムを先ほど作成したシェルスクリプトにし、そのスクリプトを経由してアプリケーションの実行可能ファイルを実行しています。これで各プロセスがなるだけ高速にアクセスできるメモリを使用して実行できます。
ピュアMPI実行の時もまったく同じ方法でNUMA最適化が可能です。ただし、上の numarun を使った場合はランク番号に対してCPUがサイクリックに割り当てられます。隣り合うランクが同じCPU内の別のコアを使用するように割り当てたい場合は numarun を変更する必要があります。