HOME > システム > HA8000クラスタシステム > HA8000クラスタシステムの紹介
HA8000クラスタシステムの紹介
「HA8000クラスタシステム」とは2008年6月に試験運用を開始した東京大学情報基盤センターのスーパーコンピューターです。このコンピューターは筑波大学、京都大学と共同で仕様を策定した「T2Kオープンスーパーコンピューター」の東大版となります。本センターによる利用の手引や各種広報などでは、特に東京大学に導入されたT2Kオープンスーパーコンピューターを意味する名称として「HA8000クラスタシステム」を用います。これは本センターのT2K オープンスーパーコンピューターの各ノードである計算機の製品名である「HITACHI HA8000-tc/RS425」の名前に由来します。
HA8000クラスタシステムの特徴
「スーパーコンピューター」と言えば「ベクトル化」に代表される特殊な最適化が必要でプログラムの汎用性も低くなる傾向がありましたが、オープンスーパーコンピューターは、多くの人に手軽に使っていただける環境を提供するため、特殊な技術を使わない設計となっています。具体的には特徴は次の3点です。
- パーソナルコンピューターやクラスタシステムなどで広く使われている x86 系プロセッサを搭載しているため、特殊なソフトウェアや最適化が不要
- Linux オペレーティングシステムを採用しているため、一般的なPCクラスタとほぼ同じ操作で使用可能
- 多数のプロセッサと高性能ノード間接続による高性能計算が可能
つまり、オープンスーパーコンピューターは、PCクラスタの利点を備えつつプロセッサ数と通信性能を強化した並列計算機ということになります。

ハードウェア構成
A)全体構成
HA8000クラスタシステムは16個のプロセッサを持つ計算機952台を高速ネットワークで接続したクラスタ型並列計算機です。全体の構成は次のようになっています。
| 項目 | 仕様 | |
|---|---|---|
| システム全体 | 総理論演算性能 | 140.1344 TFLOPS |
| 総主記憶容量 | 31.25 TB | |
| 総ノード数 | 952 (512+128+256+56)※1 | |
| ノード間ネットワーク性能 | 5 GB/s×双方向(計算ノード群A) 2.5GB/s×双方向(計算ノード群B) |
|
| ストレージ装置容量 | 1 PB (RAID6) | |
※1 952ノードのうち4ノードをログインノード、残り948ノードを計算ノードとします。ノード間ネットワーク性能について、512+128ノードが計算ノード群A 、256+56ノードが計算ノード群Bおよびログインノードです。
運用上、一個のアプリケーションが952台全体を使用することはないので、952台は512台+128台+256台+56台に分割されて接続されています。また、512台のクラスタと128台のクラスタはノード間が5GB/sで接続されており、256台のクラスタと56台のクラスタはノード間が 2.5GB/sで接続されています。5GB/s接続のクラスタをタイプA、2.5GB/sのクラスタをタイプBと呼びます。HA8000クラスタシステム全体の構成図を下に示します。
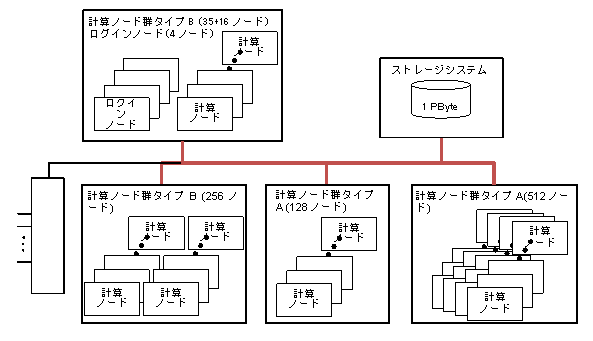
このようにHA8000クラスタシステムは4組のクラスタとストレージシステム、外部接続ルーターがネットワークで接続された構成になっています。クラスタ間およびクラスタとストレージシステムの間は1.25GB/sから7.5GB/sのネットワークで接続されています。
B)クラスタ内の構成
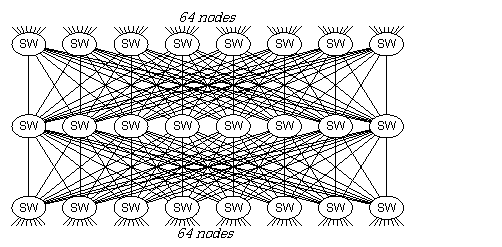
それぞれのクラスタはAMD Quad Core Opteron プロセッサを4個(合計16コア)搭載したノードをMyrinet-10Gインターコネクトで接続したものとなっています。Myrinet-10Gは1リンク1方向あたり1.25GB/s のバンド幅を持ち、双方向同時通信が可能です。タイプAのクラスタは1ノードあたり4本のMyrinet-10Gを搭載しているので5GB/s、タイプB は2本なので2.5GB/sとなります。各クラスタ内ではMyrinet-10Gは「フルバイセクションバンド幅」が確保される方法で接続されています。「フルバイセクションバンド幅」とはクラスタ内の任意の半数のノードが同時に残り半分のノードにデータを送信してもネットワーク内での競合が発生しないことを意味します。下に16ポートのスイッチを24個使用して128ノードのフルバイセクションネットワークを構成する例を挙げます。実際のHA8000クラスタシステムでは32ポートのチップを多数搭載した512ポートスイッチを使用しているため、図は実際の配線を示しているわけではありませんが、方式としては実際のシステムと同じです。多くの接続でバンド幅が確保されていることがおわかりいただけるかと思います。
C)ノードの構成
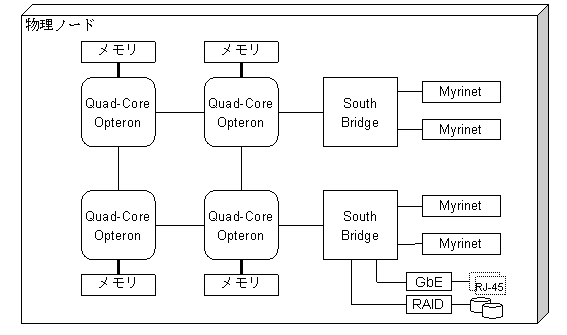
HA8000クラスタシステムの各ノードはクアッドコアプロセッサ4個、つまり16コアのCPUを搭載しています。下にノードの主な仕様を示します。 AMD Quad-Core Opteron 8356プロセッサは1クロックに4回の浮動小数点演算ができるので、2.3GHzの場合、1コアあたりの演算性能は 2.3 x 4 = 9.2GFlops です。各ノードは16個のプロセッサコアを搭載しているため、演算性能は 9.2 x 16 = 147.2GFlopsとなります。
| ノード | 理論演算性能 | 147.2 GFLOPS |
| プロセッサ数(コア数) | 4(16) | |
| 主記憶容量 | 32 GB(936ノード) 128 GB(16ノード) |
|
| ローカルディスク容量 | 250 GB(RAID1 OS領域を含む) | |
| プロセッサ | プロセッサ(周波数) | AMD Opteron プロセッサ 8356(2.3GHz) |
| キャッシュメモリ | L2:512 KB/コア L3:2 MB/プロセッサ |
|
| プロセッサコア理論演算性能 | 9.2 GFLOPS |
各ノードは下図のように構成されています。32GB(一部128GB)のメモリは4つに分割されて各プロセッサに直結されていますが、すべてのプロセッサからすべてのメモリにアクセスができます。ただし近くのメモリにアクセスする場合と遠くのメモリにアクセスする場合で性能が異なるので、アプリケーションの最適化の際には注意が必要です。
ソフトウェア構成
HA8000クラスタシステムにインストールされている主なソフトウェアは次のとおりです。
| 項目 | 仕様 |
|---|---|
| OS | RedHat Enterprise Linux 5 |
| シェル | bash/sh csh/tcsh |
| バッチシステム | NQS(現有のSR11000と同等の機能) |
| コンパイラ | 日立製作所製 最適化Fortran(77/90/95) 日立製作所製 最適化C、最適化標準C++ (全てOpenMP 2.0を含む) |
| 並列化支援 | MPI1.2通信ライブラリ(MPICH-MX) |
| 数値計算ライブラリ | MSL2、MATRIX/MPP、MATRIX/MPP/SSS BLAS、LAPACK、ScaLAPACK Intel MKL(Math Kernel Library) |
| 分子計算アプリケーション | Gaussian03 |
これらのソフトウェアはログインノードまたは計算ノードで使用できます。ログインノードではSSHによるログインおよびコマンドの対話的実行が可能です。主にプログラムの作成・編集,コンパイル,バッチジョブの投入に使用します。ログインノードの資源は多くのユーザーで共有しますので重い処理は行わないようにしてください。計算ノードはバッチジョブシステム(NQS)を通じて使用します。ジョブを投入してから実行されるまでに待ち時間がありますが、自分の順番が回ってきた際には計算ノードの資源を専有できます。通常、すべてのユーザープログラムはバッチジョブとして計算ノードで実行します。
本システムの特徴として紹介したように、広く使われている x86 系プロセッサと Linux の組み合わせですので、多数のフリーソフトウェアや市販のソフトウェアが動くことが期待できます。本センターがサービスとしてインストールしていないソフトウェアは、ユーザー個人のホームディレクトリにインストールしていただくことで利用可能です(ただし、管理者権限が必要なソフトウェアは使用できません)。