HOME > システム > SR16000 > SR16000 利用の手引き > 第1章 システム概要
第1章 システム概要
1.1 SR16000システムについて
スーパーコンピューティング部門では、以下のスーパーコンピューターシステムにより、高度かつ大規模な計算サービスを提供しています。
▶ FX10スーパーコンピュータシステム(Oakleaf-FX)
(大規模超並列スーパーコンピューターシステム)
▶ FX10スーパーコンピュータシステム(Oakbridge-FX)
(長時間ジョブ実行用並列スーパーコンピューターシステム)
▶ SR16000システム(SMP)(Yayoi)
(大規模 SMP 並列スーパーコンピューターシステム)
この利用の手引きは「SR16000システム」について解説します。SR16000は1ノードあたり32個コアを備えたノードを複数台搭載しており、ノードを並列に動作されるのと同時にノード内でも並列処理を行うことが可能なシステムです。

1.2 ハードウェア構成
本章ではSR16000のハードウェア構成を紹介します。
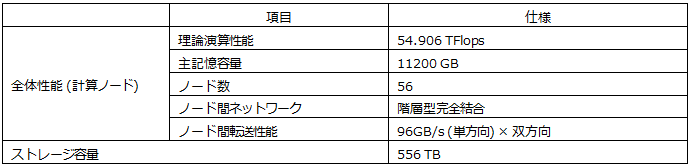
1.2.1 全体構成
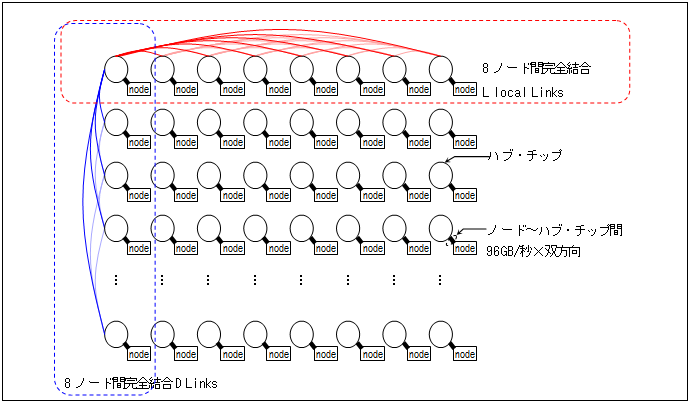
SR16000は1ノードあたり32個のコアを備えた計算機(計算ノード)を56台、高速なネットワークで接続したシステムです。全体構成は以下の表のようになっています。
表1-2-1 SR16000全体性能
1.2.2 ノードの構成
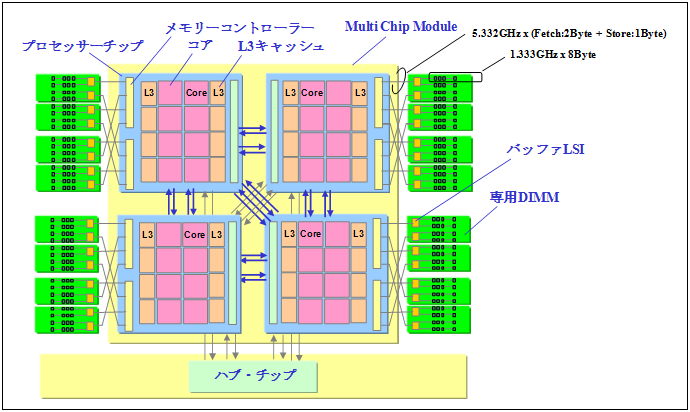
SR16000のノードは、4個のPOWER7プロセッサ(32個コア)、200GBのメモリを搭載しています。POWER7プロセッサの特徴として、1コアあたり30.64GFlops、ノードあたりでは980.48GFlopsの高い演算性能を有しています。
また、1台のコア内で複数のスレッドを実行できるSMT(Simultaneous Multi-Threading)機能を有しており、1台のコアを仮想的に2または4台のコアとして扱うことができます。なお、本センターではSMT設定を2(1台のコアを仮想的に2台のコアとして作動)としています。
表1-2-4 SR16000全体性能

1.3 ソフトウェア構成
SR16000にインストールされている主なソフトウェアは以下の表のとおりです。
表1-3-1 ソフトウェア一覧
| 項目 | ソフトウエア名 |
| OS | AIX 7.1 |
| バッチシステム | NQS 互換機能 |
| コンパイラ | 日立製作所製 最適化 FORTRAN90, 最適化 C, 最適化標準 C++ IBM XL C/C++ Enterprise Edition for AIX Java, GNU コンパイラ |
| 並列化支援 | MPI, OpenMP |
| 数値計算ライブラリなど | MSL2, MATRIX/MPP, MATRIX/MPP/SSS, BLAS, LAPACK, ScaLAPACK, FFTW, SuperLU |
| 分子計算アプリケーション | Gaussian16 |
| フリーソフトウェア | bash, tcsh, zsh, emacs, autoconf, automake, bzip2, cvs, gawk, gmake, gzip, make, less, sed, tar, vim など |
これらのソフトウェアはログインノードまたは計算ノードで使用できます。ログインノードではSSHによるログインおよびコマンドの対話的実行が可能です。主にプログラムの作成・編集、コンパイル、バッチジョブの投入に使用します。ログインノードの資源は多くのユーザーで共有しますので重い処理は行わないようにしてください。計算ノードはバッチジョブシステム(NQS)を通じて使用します。ジョブを投入してから実行されるまでに待ち時間がありますが、自分の順番が回ってきた際には計算ノードの資源を専有できます。通常、すべてのユーザープログラムはバッチジョブとして計算ノードで実行します。
SR16000 にインストールしていないソフトウェアは、ユーザー個人のホームディレクトリにインストールしていただくことで利用可能です(ただし、管理者権限が必要なソフトウェアは使用できません)。
1.4 サービス概要
SR16000では研究者が個人単位で利用するための「パーソナルコース」によるサービスのみ行っています。パーソナルコースには、最大で利用できるノード数により複数のコースを用意しています。また、上位コースは下位コースを含みますので、例えばパーソナルコース3の利用者が4ノードのジョブを実行することも可能となっています。
表1-4-1 パーソナルコースの種類
