HOME > システム > SR16000 > SR16000 利用の手引き > 第5章 並列計算
第5章 並列計算
5.1 概要
- 共有メモリを用いた並列化
- ネットワーク通信による並列化
SR16000 では両方の並列化手法が使用できます。ただし、本センターでは複数のノードを用いた並列計算を行っていただくことに重点を置いているため、共有メモリを用いた並列化のみを行い、ノード間の通信を行わないアプリケーションを実行するためのみのコースは用意しておりません(最適化などのため1ノードジョブを流す必要性もありますので、単一ノードジョブも実行は可能です)。つまり、本システムにおいては主にMPI通信によるアプリケーションの並列化と、さらに必要に応じて、ノード内での並列化を最適化するために共有メモリを用いた並列化を行うことになります。
本章では共有メモリを用いた並列化、MPIによる並列化、およびその双方を用いた並列化についてその概念を説明します。本章で説明する概念を理解することはコンパイラやバッチジョブシステムを正しく使用するために重要となります。
5.2 共有メモリを用いた並列化
5.2.1 自動並列化
自動並列化はプログラムの並列化をすべてコンパイラに任せる方法です。コンパイラはプログラムの並列性を自動的に見つけ出し並列化されたコードを生成します。
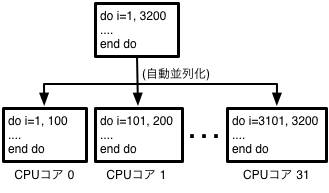
図5-2-1 自動並列化のイメージ
この方法では逐次プログラムを書き換えることなく並列化が可能です。もっとも容易な並列化手法ですが、並列性を意識せずに書かれたプログラムは本質的に並列化が難しいコードになる傾向が強いため高い並列性能が得られない場合があります。
性能向上のために自動並列化のためのコンパイラへのヒントをソースコード中に記述できるコンパイラも存在しますが、そのようなコードはコンパイラ依存になってしまいます。ソースコードに並列化指示を記述する場合は次に説明するOpenMPを使用することをお勧めします。SR16000 で導入された日立製作所製のコンパイラでは自動並列化の一種として「要素並列化」と呼ばれる機能が提供されており、IBM製C/C++コンパイラでも自動並列化機能が提供されております。利用方法は次章で紹介します。
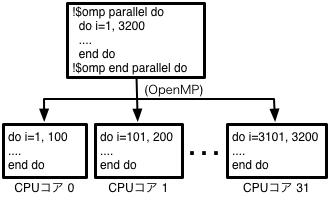
5.2.2 OpenMP
OpenMPはプログラマによってコンパイラに並列化を指示するための言語拡張仕様です。多くのコンパイラに実装されているためほとんどの並列計算機で使用可能な一般的な方法となっています。この方法ではユーザーが並列化方法を制御できるため正しくOpenMPコードを挿入した場合の性能は自動並列化より高くなることが期待できます。反面、誤った並列化指示は計算結果の誤りにもつながるので注意が必要です。
SR16000 では日立製作所製の最適化コンパイラ、IBM製C/C++コンパイラにOpenMPオプションを付けることで使用できます。使用方法の詳細は次章で紹介します。
5.2.3 並列化されたライブラリの使用
BLASなどのライブラリの中にはライブラリ自体が並列化されているものがあります。ライブラリの中での計算が実行時間の大半を占めるようなアプリケーションでは並列化されたライブラリをリンクするだけで十分な並列化効率が得られる場合もあります。
並列化されたライブラリを使用するときは呼び出し元の並列化方法に注意する必要があります。例えばOpenMPで並列化された部分からさらに並列化されたライブラリを呼び出すとプロセッサ数の2乗の数のスレッドが生成され性能が大きく低下する可能性があります。
5.2.4 日立製作所独自仕様の並列化
日立製作所製のコンパイラではSECTION型要素並列化と呼ばれる並列化手法が提供されています。旧システムの HA8000 や SR11000 など、本センターの他のマシンでこのSECTION型要素並列化を使用して並列化を行ったプログラムをお持ちの方は SR16000 でも引き続きSECTION型要素並列化にて使用できます。新しく作成するプログラムに関しては特殊な事情がない限り、なるべく汎用的な方法での並列化をお勧めします。
5.3 MPIによる並列化
MPIによる並列プログラムはSPMD(Single Program Multiple Data)モデルと呼ばれ、単一のプログラムを多数のノードで実行し、それぞれのノード(CPUコア)で動くプログラムが自身のノードで行うべき計算を判断して実行することにより並列に計算を行います。図5-3-1にMPIを使ったプログラムのイメージ(1ノードあたり1プロセスで実行した場合の例)を示します。
この例でのプログラムの実行は各ノードで行われますが、図をよく見ると2つのノードで実行されるプログラムはまったく同じ内容であることがわかります。このようにMPIでは基本的にすべてのノードで同じプログラムを実行し、プログラムの中で自身のランク(ノード番号あるいはプロセス番号)を調べてそれに応じた処理を行います。
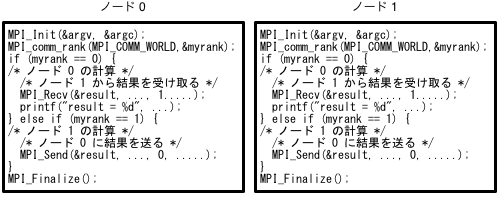
図5-3-1 MPIのプログラム例
SR16000 ではノード間およびノード内のプロセス間通信にMPIが使用できます。ノード内通信、ノード間通信ともにMPIで行う場合は、ノード内外の区別をすることなくすべての並列化作業をMPI通信によって行います。このようなプログラムを1ノードあたり複数のプロセスが配置されるような設定で実行すればMPI通信ライブラリが自動的にノード内およびノード間それぞれに適した方法で通信を行います。このような実行形態を一般的にピュアMPI(またはフラットMPI)と呼びます。
5.4 共有メモリによる並列化とMPI並列化の併用
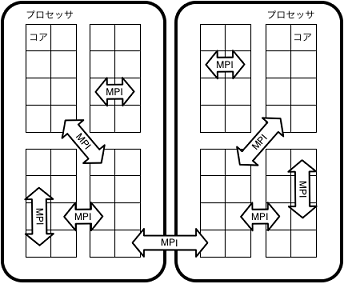
前節で説明したピュアMPIでは各プロセスが行う通信が細かくなりすぎるなどの問題で高い性能が得られない場合があります。このような場合はOpenMPや自動並列化などの共有メモリを用いた並列化とMPIを併用することになります。例えば、1ノードにOpenMPで8スレッドに並列化したプロセスを4つ生成することで32個の物理コアを使用するような方法が考えられます。このような実行方法を「MPI+OpenMPハイブリッド実行」などと呼びます。
このような場合は、MPIプログラムを自動並列化したり、MPIプログラムにOpenMP指示行を加えたりしてプログラムをコンパイルします。実行時にはプロセスあたりの並列化数(スレッド数)とMPIプロセス数双方を正しく設定する必要があります。
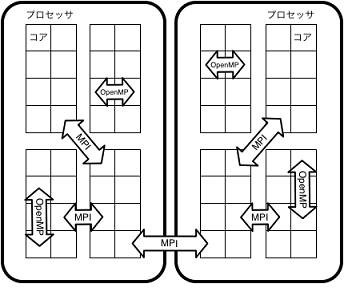
図5-4-1 MPIとOpenMPの併用イメージ