
東京大学情報基盤センターが Society 5.0 実現へ向けた
「計算・データ・学習」融合スーパーコンピュータシステムの導入を決定
発表のポイント
- 東京大学情報基盤センターがピーク性能33.1 PFLOPSの超並列システム「Wisteria/BDEC-01」の導入を発表
- シミュレーションノード群(Odyssey)とデータ・学習ノード群(Aquarius)を有し、「計算・データ・学習」融合により、Society 5.0実現に貢献する
- シミュレーションノード群(Odyssey)は、世界最高性能を有するスーパーコンピュータ「富岳」と同じ富士通株式会社の「FUJITSU Processor A64FX」を7,680基搭載、ピーク性能は25.9 PFLOPS
- データ・学習ノード群(Aquarius)にはインテル ディープラーニング・ブースト・テクノロジーを有するインテル社製「第3世代Xeonスケーラブルプロセッサ(開発コード名Ice Lake)」90基、NVIDIA社の最新GPUである「NVIDIA A100 Tensor コア GPU」を360基搭載、ピーク性能7.2 PFLOPS
- シミュレーションノード群(Odyssey)とデータ・学習ノード群(Aquarius)の合計ピーク性能は、33.1 PFLOPS であり、2020年11月のTOP500リストにおいて「富岳」に続き国内第2位の性能に相当する
発表概要
東京大学情報基盤センター(センター長:田浦健次朗)は、東京大学柏Ⅱキャンパスに建設中の総合研究棟(情報系)に、「計算・データ・学習」融合スーパーコンピュータシステム「Wisteria/BDEC-01(ウィステリア/ビーデックゼロワン)」を導入することを決定しました。2021年5月14日に共同利用システムとして稼働開始します。
「Wisteria/BDEC-01」はシミュレーションノード群(Odyssey(オデッセイ))とデータ・学習ノード群(Aquarius(アクエリアス))の2つの計算ノード群を有したシステムです。総ピーク性能はそれぞれ25.9 PFLOPS(ペタフロップス、注1 )(Odyssey)、7.2 PFLOPS(Aquarius)、合計33.1 PFLOPSであり、2020年11月のTOP500リスト( 注2 )では「富岳」に続く国内第2位の性能に相当します。最先端の研究だけでなく、計算科学・データ科学・機械学習やHPC分野の人材育成にも共同利用される予定です。
本システムの導入および運用により、特に「計算・データ・学習」融合が推進され、サイバー空間(仮想)とフィジカル空間(現実)を高度に融合させたSociety 5.0( 注3 )の実現に大きく貢献することが期待されます。
発表内容
背景
東京大学情報基盤センターは1965年に東京大学大型計算機センター(以下、「当センター」)として設立されました。以来50年余り、全国共同利用施設、「学際大規模情報基盤共同利用・共同研究拠点(JHPCN、 注4 )」の中核拠点、「革新的ハイパフォーマンス・コンピューティング・インフラ(HPCI、注5 )」の構成機関として、国内外の産学官の各機関で実施されているスーパーコンピュータを使用した大規模シミュレーションによる計算科学・計算工学の研究の発展に貢献してまいりました。
2020年12月現在、当センターでは4式(Reedbush-H、Reedbush-L、Oakforest-PACS、Oakbridge-CX)のシステムを運用しており、総利用者数は学内外を合計して約2,600名、そのうち55%は学外利用者です。各システムは、高い計算性能、ユーザーフレンドリなプログラム開発環境、安定した運用が利用者に高く評価されています。HPCIによる「新型コロナウイルス感染症対応HPCI臨時公募課題」においても全14課題のうち6課題が当センターのシステムを使用して実施されています。
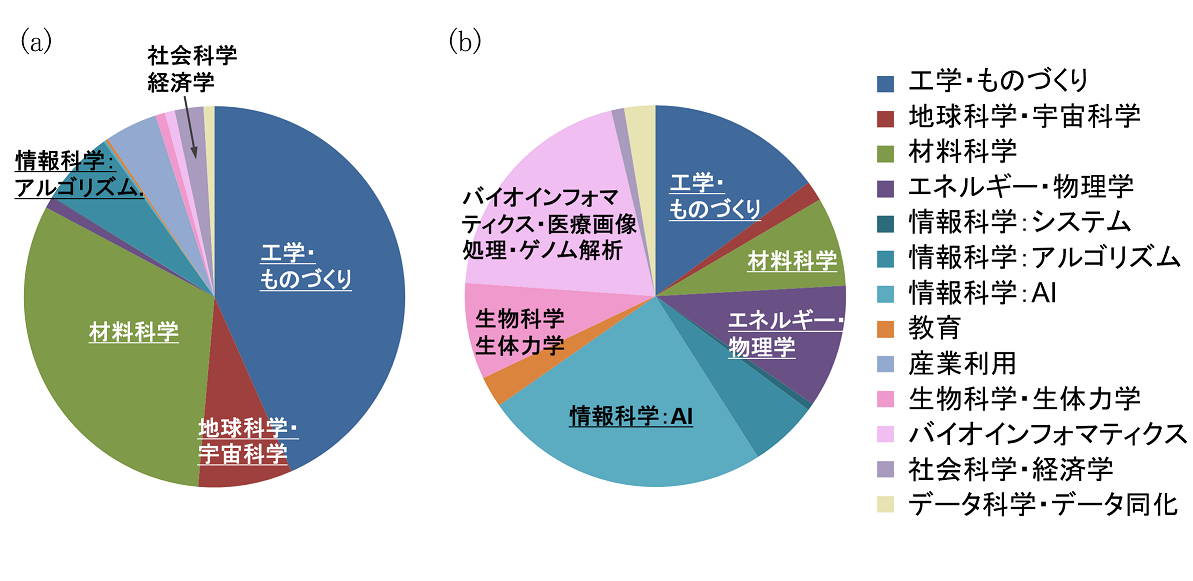 図1 実行ジョブノード時間の分野別比率(2019年度)、(a)Reedbush-U(Intel Xeon E5-2695v4 (Broadwell-EP: BDW))、(b)Reedbush-H(Intel Xeon E5-2695v4 (BDW) + NVIDIA Tesla P100(ノード当たり2GPU))
図1 実行ジョブノード時間の分野別比率(2019年度)、(a)Reedbush-U(Intel Xeon E5-2695v4 (Broadwell-EP: BDW))、(b)Reedbush-H(Intel Xeon E5-2695v4 (BDW) + NVIDIA Tesla P100(ノード当たり2GPU))計算科学が「第三の科学(The Third Pillar of Science)」と呼ばれるようになって久しいですが、近年は様々なデータを活用することによって更に新しい科学を開拓する試みが始まっています。当センターの各システムの利用分野では、図1(a)に示すように,①工学・ものづくり、②地球科学・宇宙科学、③材料科学が長年にわたって利用時間の合計80%以上を占めてきましたが、当センター初のGPU搭載システムとして2017年4月に運用を開始したReedbush-H(データ解析・シミュレーション融合スーパーコンピュータシステムGPU搭載ノード群)は人工知能、医療画像処理を中心としたバイオインフォマティクスなど、より多様な分野で使用されています(図1(b))。
また、本来計算科学・計算工学用途を念頭において導入されたOakforest-PACS(OFP)、Oakbridge-CX(OBCX)においても図2(a、b)に示すようにデータ科学、バイオインフォマティクス分野の利用が多くなっています。特にOBCXは全1,368ノードのうち、128ノードに高速SSD(Solid State Drive,ノード当たり容量1.6TB)を搭載しており、データ科学関係のソフトウェア群も充実していることから、バイオインフォマティクスを中心としたデータ科学分野の利用が増加しつつあります。
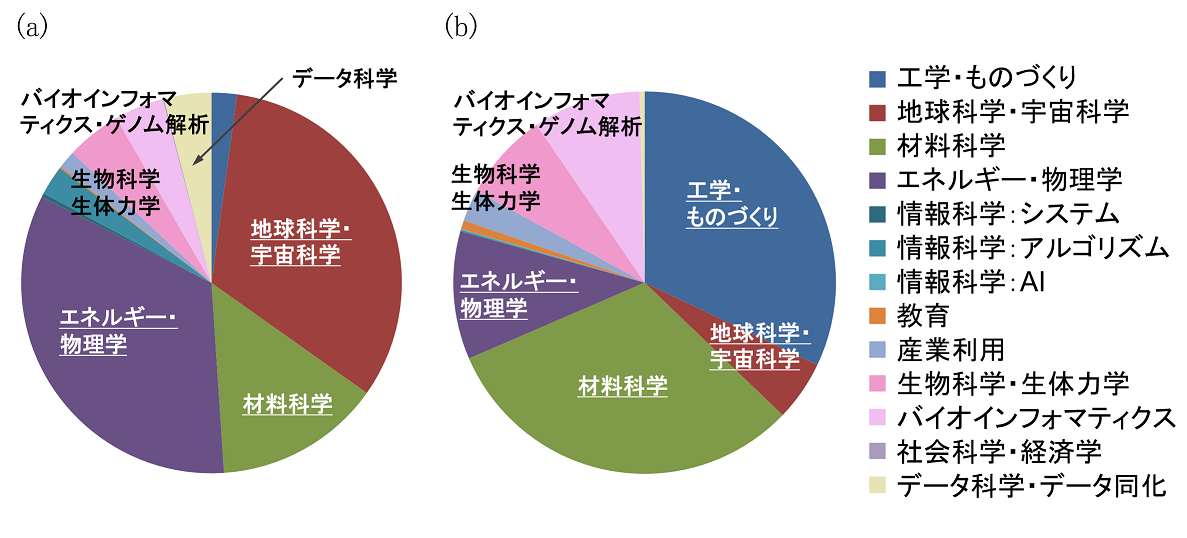 図2 実行ジョブノード時間の分野別比率(2019年度、OBCX:2019年10月~2020年9月末)、(a)Oakforest-PACS(OFP、Intel Xeon Phi 7250 (Knights Landing))、(b)Oakbridge-CX(OBCX、Intel Xeon Platinum 8280 (Cascade Lake-SP))
図2 実行ジョブノード時間の分野別比率(2019年度、OBCX:2019年10月~2020年9月末)、(a)Oakforest-PACS(OFP、Intel Xeon Phi 7250 (Knights Landing))、(b)Oakbridge-CX(OBCX、Intel Xeon Platinum 8280 (Cascade Lake-SP))Society 5.0の実現には様々なデジタル革新・イノベーションが不可欠です。スーパーコンピューティングは、従来の計算科学・計算工学シミュレーションに加えて、データ科学、機械学習等の知見を融合した新しい手法を適用することによって、サイバー空間とフィジカル空間の融合を通じたSociety 5.0実現に大きく貢献すると期待されています。
このような背景のもと、当センターでは2015年頃からこのような状況を念頭において、「計算・データ・学習(Simulation+Data+Learning, S+D+L)」融合を実現するプラットフォームとして「計算・データ・学習」融合スーパーコンピュータシステム(通称「BDEC(Big Data & Extreme Computing)システム」)構築を目指して、様々な研究開発を進めてきました。現在当センターで運用中のReedbush(データ解析・シミュレーション融合スーパーコンピュータ、2016年7月運用開始)、Oakbridge-CX(大規模超並列スーパーコンピュータシステム、同2019年7月)は、いずれも「BDECシステム」設計のためのプロトタイプ、実証システムとしても位置づけられています。
詳細
新規導入されるWisteria/BDEC-01システムは、シミュレーションノード群(Odyssey)とデータ・学習ノード群(Aquarius)を有し、「計算・データ・学習」融合により、Society 5.0実現に貢献するものです。システム製作は富士通株式会社(本社:東京都港区、代表取締役社長:時田隆仁)が実施いたします。
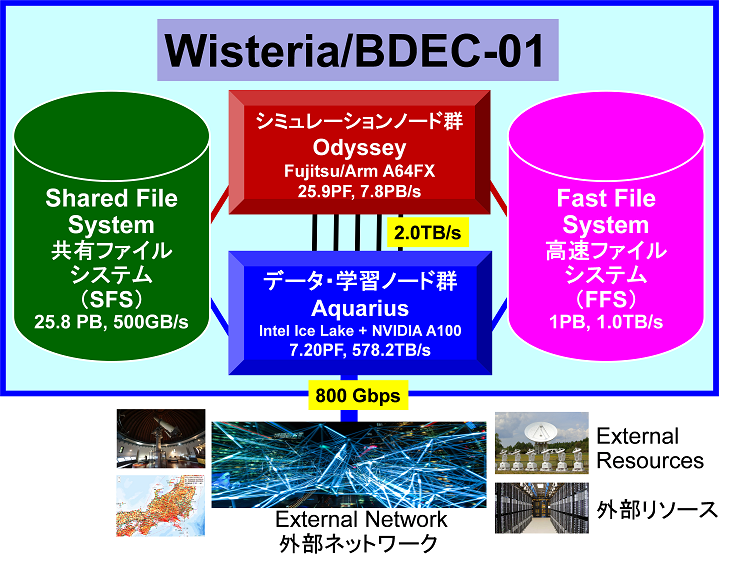 図3 Wisteria/BDEC-01の概要
図3 Wisteria/BDEC-01の概要シミュレーションノード群(Odyssey)は「FUJITSU Supercomputer PRIMEHPC FX1000」20ラックから構成され、「A64FX」を7,680ノード(368,640コア)搭載しています。「A64FX」は、Armv8.2-A命令セットアーキテクチャーをスーパーコンピュータ向けに拡張した「SVE(Scalable Vector Extension)」を、世界で初めて実装したプロセッサです。最先端の7nmプロセスで製造され、48個の演算コアと2個または4個のアシスタントコア( 注6 )を有し、倍精度浮動小数点演算で3.3792 TFLOPSの理論ピーク性能を実現します。合計ピーク性能は25.9 PFLOPSです。各ノードは32 GiBのHBM2メモリを搭載し、シミュレーションノード群(Odyssey)の総メモリ容量は240 TiB、総メモリバンド幅は7.8 PB/秒です。各ノードはバイセクションバンド幅が13.0 TB/秒のノード間相互結合ネットワーク( 注7 )(TofuインターコネクトD)で結合されています。
データ・学習ノード群(Aquarius)は、富士通株式会社が開発する「FUJITSU Server PRIMERGY GX2570」の次期モデル45ノードによって構成されています。各ノードは汎用CPU 2基(インテル社製「第3世代Xeonスケーラブルプロセッサ(開発コード名Ice Lake)」))、演算加速装置(GPU)8基(「NVIDIA A100 Tensor コア GPU」)から構成されており,ノード間インターコネクトにはNVIDIA Mellanox HDR InfiniBandネットワークが採用されています。データ・学習ノード群(Aquarius)の合計ピーク性能は7.2 PFLOPS、総メモリ容量は36.5 TiB、総メモリバンド幅は578.2 TB/秒です。各ノードは、データ転送速度が200 Gbpsの帯域を有するInfiniBand HDR を4リンク用いて、フルバイセクションバンド幅( 注8 )を持つノード間相互結合ネットワークで結合されています。さらに、外部接続のために 25 Gbps Ethernet インタフェースも有しています。
FEFS(Fujitsu Exabyte File System)による、共有ファイルシステム( 注9 )(容量:25.8 PB、データ転送速度:0.504 TB/秒)およびSSDを搭載した高速ファイルシステム( 注10 )(容量:1.0 PB、データ転送速度:1.00 TB/秒)を有し、それぞれシミュレーションノード群(Odyssey)、データ・学習ノード群(Aquarius)からアクセスし、大規模なデータを高速に処理することが可能です。
シミュレーションノード群(Odyssey)とデータ・学習ノード群(Aquarius)は、合計160本のInfiniBand EDR(100Gbps)を用いて2.0 TB/秒のネットワークバンド幅で結合されています。また、データ・学習ノード群(Aquarius)は合計800 Gbpsのネットワーク転送速度で外部との通信が可能です。
ソフトウェアとしては、Fortran、C/C++コンパイラ、Pythonインタープリタ、MPI通信ライブラリ等を使用できます。計算科学、データ科学、機械学習、人工知能等幅広い分野のライブラリ、ツール、アプリケーションを提供します。オープンソースアプリケーションとしては、OpenFOAM(数値流体力学)、MateriAppsアプリケーション群(物質科学)、東京大学生産技術研究所で開発された革新的シミュレーションソフトウェア群などを利用できます。
また、当センターで開発した「ppOpen-HPC(自動チューニング機構を有するアプリケーション開発・実行環境)」、「h3-Open-BDEC(「計算+データ+学習」融合のための革新的ソフトウェア基盤)」を利用し、高性能なアプリケーションを容易に開発することが可能です。計算科学シミュレーションは多くの場合、非線形な問題を扱うため、多数のパラメータスタディが必要です。Wisteria/BDEC-01では、機械学習による最適パラメータ推定を、外部から取り込んだ実験・観測データによる同化と組み合わせて、正確な解をより短時間で求めることを目指しています(図4)。h3-Open-BDECはそのようなアプリケーションの開発を支援する機能とともに、シミュレーションノード群(Odyssey)とデータ・学習ノード群(Aquarius)が協調したワークロードの実行を支援する機能も提供します。
運用
Wisteria/BDEC-01は2021年5月14日から稼働を開始し、数ヶ月の実験的運用と特別プログラムによる利用を経て、正式運用を開始します。2021年10月よりHPCI、JHPCN を始めとする各種共同利用・共同研究プログラムに供される予定です。計算科学・データ科学・機械学習およびHPC分野の人材育成にも利用され、講義・演習、並列プログラミング講習会にも利用されます。また、2020年度から試験的に開始した萌芽共同研究公募課題「AI for HPC:Society 5.0実現へ向けた人工知能・データ科学による計算科学の高度化」においても、中核的なシステムとして、特に若手を中心とした研究者の育成にも貢献します。
シミュレーションノード群(Odyssey)、データ・学習ノード群(Aquarius)を使用し、計算科学、データ科学、人工知能・機械学習の幅広いアプリケーションをカバーすることによって、最先端の科学技術計算を支える重要なインフラとなることは言うまでもありませんが、東京大学各部局(生産技術研究所、地震研究所、大気海洋研究所、物性研究所)、理化学研究所等との協力のもと、ものづくり、地球科学分野(固体地球、大気・海洋)、物質科学などの分野における「計算・データ・学習」融合により、Society 5.0実現に向けた重要なプラットフォームとなることが期待されます。
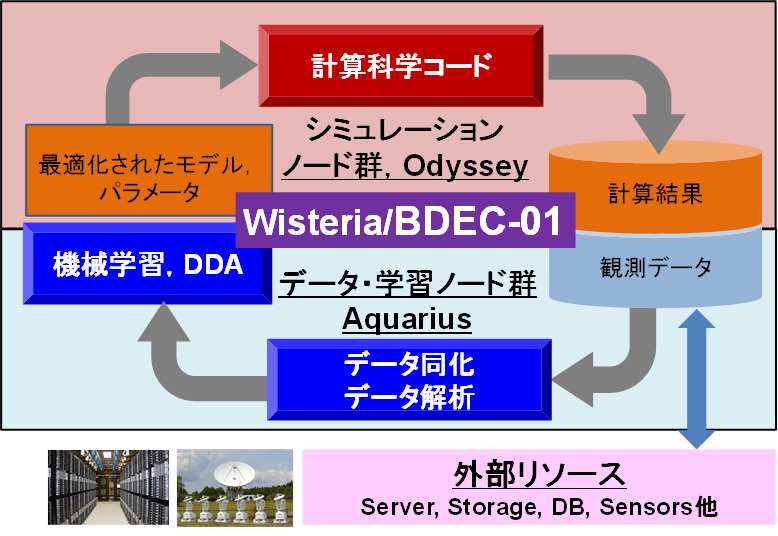 図4 Wisteria/BDEC-01利用による「計算・データ・学習」融合のイメージ
図4 Wisteria/BDEC-01利用による「計算・データ・学習」融合のイメージ名称について
近年、当センターのシステムはYayoi、Oakleaf、Oakbridge、Oakforestなど設置キャンパスに由来する植物を名称として使用してきました。Wisteria(紫藤)は柏市にある手賀沼に伝わる「藤姫伝説」に因んでおり、藤の蔓の如く、「計算・データ・学習」融合のための各ノード群、ファイルシステム群が緊密に結合していく様を示しています。
シミュレーションノード群(Odyssey)とデータ・学習ノード群(Aquarius)は、それぞれアポロ13号の司令船(Command Module、CM)と月着陸船(Lunar Module、LM)の名称です。地球はいま新型コロナ感染症により未曾有の危機に晒されています。OdysseyとAquariusがアポロ13号乗組員の地球への無事帰還をサポートしたごとく、Wisteria/BDEC-01も地球と人類を護り、救うことに貢献できれば、という願いが込められています。
問い合わせ先
東京大学情報システム部 情報戦略課総務チーム(情報基盤センター事務担当)
TEL:03-5841-2710 E-mail:itc-press AT itc.u-tokyo.ac.jp ( AT をアットマークに置き換えてください)
用語解説
(注1)PFLOPS(ペタフロップス)
計算機の処理性能の指標としてFLOPS(Floating-point Operations Per Second)、すなわち1秒間に実行可能な浮動小数点数演算回数(実数演算回数)が用いられます。PFLOPS (Peta FLOPS) = 1015 FLOPSです。
(注2)スーパーコンピュータの性能、ランキングについて
TOP500 は、世界のスーパーコンピュータの性能を定期的に収集し、評価するプロジェクトのことです。目的は、ハイパフォーマンスコンピューティング(HPC、高性能計算)における傾向を追跡・分析するための信頼できる基準を提供することであり、評価にはHPL(High Performance Linpack)という大規模な連立一次方程式を解くためのベンチマークプログラムが使用されています。TOP500 が初めて公開されたのは1993年で、以降年2回(International Supercomputing Conference(ISC)(6月、ドイツ)およびSupercomputing Conference(SC)(11月、アメリカ))更新されています。リストの作成はマンハイム大学、テネシー大学、ローレンス・バークレイ米国立研究所の研究者らが行っています。TOP500 から派生して、スーパーコンピュータの様々な性能を計測し、評価する試みとして、Green 500、Graph 500、HPCG、HPC AI500などがあります。
(注3)Society 5.0
Society 5.0とは、サイバー空間(仮想空間)とフィジカル空間(現実空間)を高度に融合させたシステムにより、経済発展と社会的課題の解決を両立する、人間中心の社会(Society)でです。狩猟社会(Society 1.0)、農耕社会(Society 2.0)、工業社会(Society 3.0)、情報社会(Society 4.0)に続く、新たな社会を指すもので、第5期科学技術基本計画において我が国が目指すべき未来社会の姿として提唱されました。Society 5.0の実現にはIoT(Internet of Things)、ロボット、AI(人工知能)、ビッグデータといった社会の在り方に影響を及ぼすデジタル革新・イノベーションが不可欠です。スーパーコンピューティングは、従来の計算科学・計算工学シミュレーションに加えて、データ科学、機械学習等の知見を融合した新しい手法を適用することによって、サイバー空間(仮想空間)とフィジカル空間(現実空間)を高度に融合したシステムを形成し、Society 5.0が目指す人間中心の社会の実現に大きく貢献すると期待されます。
(注4)JHPCN
学際大規模情報基盤共同利用・共同研究拠点 (JHPCN)は、東京大学情報基盤センターを中核拠点として、スーパーコンピュータを設置・運用する8大学の情報基盤センター群からなる「ネットワーク型」共同利用・共同研究拠点です。超大規模数値計算系応用分野、超大規模データ処理系応用分野、超大容量ネットワーク技術分野、および超大規模情報システム関連研究分野を対象としており、HPCIとも一部の計算資源の運用について連携して実施しています。
(注5)HPCI
革新的ハイパフォーマンス・コンピューティング・インフラ(High Performance Computing Infrastructure)。「富岳」コンピュータをはじめとする、国内主要スーパーコンピュータ資源の科学技術計算への共同利用を統一的に管理運用する文部科学省のプログラムです。スーパーコンピュータを必要とする科学技術計算プロジェクトを年度単位で公募し、審査結果に基づいて利用資源割り当てが決定されます。
(注6)アシスタントコア
アシスタントコアは、システムノイズの低減、通信と計算のオーバーラップ等によって、各ノード48個の計算コアを計算に専念させ、計算効率を向上させる働きを有しています。
(注7)相互結合ネットワーク
並列計算機システムにおいて、各計算処理を行うサーバ(ノードと呼ぶ)間を結合するためのネットワークのことです。一般的なEthernet等と異なり、高性能並列処理のために、拡張性があり大容量高速データ交換を実現可能な高バンド幅・低遅延のネットワークが求められます。
(注8)フルバイセクションバンド幅
フルバイセクションバンド幅の構成とはクラスタ内の任意の半数のノードが同時に残り半分のノードにデータを送信してもネットワーク内での競合が発生しないネットワーク構成のことです。
(注9)並列ファイルシステム
システムで利用するデータやプログラムを格納するストレージシステムです。
(注10)高速ファイルシステム
高速にデータの読み書きが可能なSSDで構成されたストレージシステムです。